
ИИ научился легко решать сложнейшие уравнения, которые описывают устройство Вселенной
Дифференциальные уравнения в частных производных встречаются в самых разных аспектах физико-математического моделирования. Они позволяют рассчитывать состояния весьма сложных систем, но их решение всегда было ресурсоемкой задачей. Благодаря специально созданной нейросети этот процесс значительно ускорился и мощности суперкомпьютеров можно будет перенаправить на другие важные задачи.

Большинство студентов технических специальностей встречают уравнения математической физики (УМФ), или дифференциальные уравнения в частных производных, лишь однажды. Пройдя их во время обучения, об этом сложном, но мощном инструменте почти всегда забывают. И лишь некоторые инженеры используют их регулярно. Речь идет, например, о моделировании воздушных потоков в аэродинамике, описании движения тектонических плит, расчете положения планет или метеорологии.
Как правило, для решения подобных уравнений применяют мощные вычислительные комплексы — суперкомпьютеры или сети распределенных вычислений. Для многих ученых, работающих в не самых богатых на финансирование отраслях, такие расчеты всегда были головной болью. Понимая важность появления нового инструмента для выполнения подобных задач, американские математики и программисты обратились к технологиям искусственного интеллекта.
Коллектив ученых из Калифорнийского технологического института (Caltech) и Университета Пердью разработал высокоэффективный нейросетевой алгоритм для работы с УМФ. При его использовании удалось достичь огромного прироста скорости решения уравнений — в некоторых случаях на несколько порядков. Например, на матрице 256х256 их Нейронный оператор Фурье (Fourier neural operator, FNO) выдал результат за 0,005 секунды при решении уравнений Навье — Стокса. Наиболее распространенный алгоритм, используемый ранее, рассчитывал те же условия за 2,2 секунды.
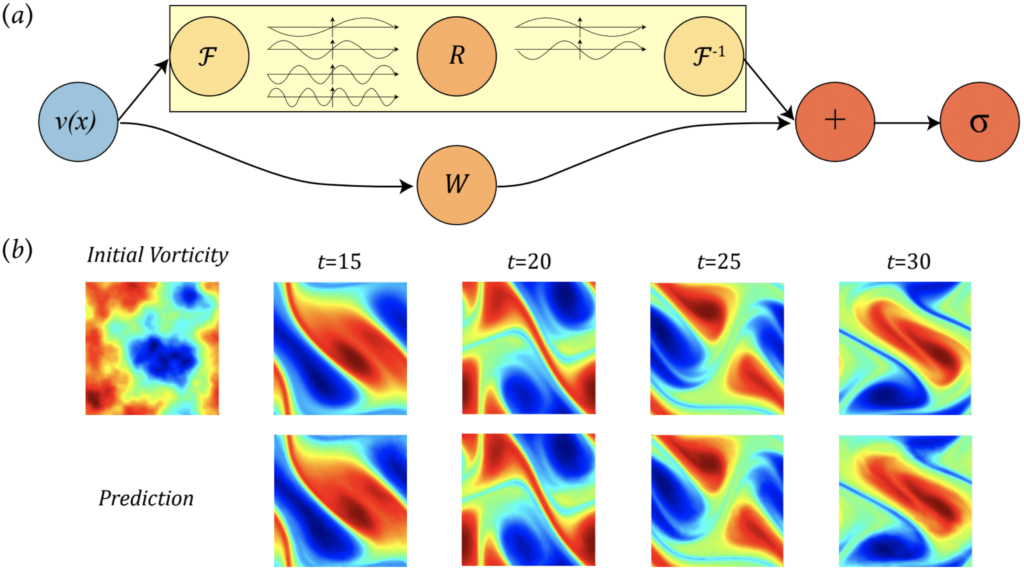
Эти дифференциальные уравнения встречаются повсеместно — точнее, с их помощью можно описать практически любую динамическую систему. Появление доступного и эффективного метода их решения может существенно продвинуть вперед самые разные области науки. А уж применимость такого «искусственного интеллекта» в инженерных разработках точно не заставит себя ждать. Полное описание своей работы американские ученые опубликовали на портале arXiv.
Нельзя сказать, что создатели FNO первыми догадались решать дифференциальные уравнения в частных производных с помощью нейросетей и машинного обучения. Нет, так делали и раньше. Однако существующие алгоритмы приходилось обучать заново на каждый новый набор вычислений — даже при изменении свойств похожих жидкостей. Разработка ученых из Калтеха и Пердью позволяет выполнить «тренировку» лишь однажды и обсчитывать самые разные модели. Секрет эффективности FNO гениален и одновременно прост.
Основа работы любой нейросети — аппроксимация функции, ее приближение. Искусственный интеллект оперирует в своих вычислениях не точными значениями, а диапазоном величин, который позволяет принять решение или выдать результат, не прибегая к ресурсоемким и сложным уточнениям. Иными словами, нейросети во время обучения вырабатывают упрощенные формулы, результаты которых достаточно точны, чтобы применяться на практике.
Обычно работающие с графиками функций нейросети оперируют значениями в евклидовом пространстве. Для того чтобы упростить задачу, авторы FNO решили не переводить волновые функции в привычные графики, а «научить» алгоритм работать напрямую с преобразованиями Фурье. Это позволило не только прибавить скорость вычислений, но и снизить количество ошибок: их теперь на 30% меньше, чем в прежних алгоритмах.
Нашли опечатку? Выделите фрагмент и нажмите Ctrl + Enter.