
Яндекс Лавка начала добавлять информацию о товарах в приложение с помощью YandexGPT
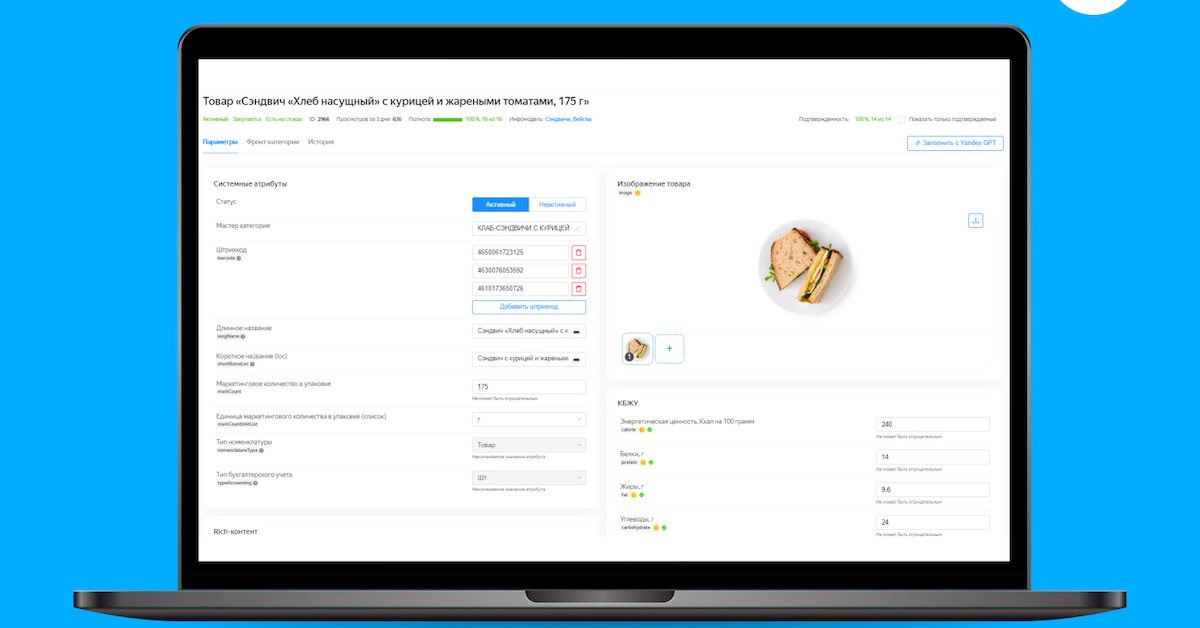
Яндекс Лавка начала добавлять информацию о товарах в свое приложение с помощью YandexGPT и технологии распознавания текста OCR (Optical Character Recognition, с англ. — оптическое распознавание символов). Они анализируют фотографию этикетки каждого продукта и самостоятельно заполняют его карточку. Это позволит сервису в три раза увеличить скорость обновления информации о товарах, упростит работу контент-менеджерам, а покупатели смогут быстрее узнавать о новинках в Лавке.
Теперь чтобы добавить информацию о новом товаре достаточно сделать фото его упаковки и загрузить в контент-систему Лавки. Технология распознавания текста проанализирует фотографию и переведет ее в текст, а нейросеть YandexGPT возьмет из него характеристики товара и заполнит его карточку.
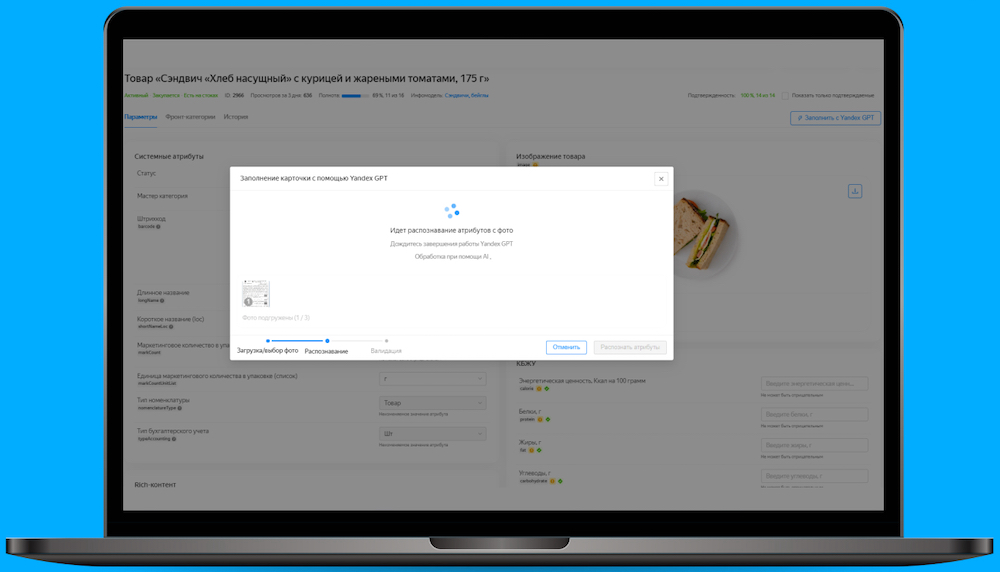
Раньше на это уходило больше времени — контент-менеджеру нужно было вручную переносить в систему всю информацию о товаре с этикетки, а это около 20 характеристик – состав, вес, производитель и другое.
Чтобы научить нейросеть работать с данными о товарах, Лавка показала ей 16 тысяч уже готовых карточек. Нейросеть продолжит обучаться и во время работы — в этом ей помогут контент-менеджеры. Они будут проверять заполненные YandexGPT карточки, исправлять их, если понадобится, и показывать нейросети. Так Лавка планирует еще быстрее и точнее работать с информацией о новых товарах.
В Яндексе сообщили, что аналогичное решение могут реализовать у себя и другие компании, запросив доступ к YandexGPT через API.
В дальнейшем, с помощью YandeхGPT Лавка планирует решать больше разных задач, связанных с текстами, — например, создавать подробные описания товаров и давать советы, с чем их можно сочетать.